
The Point(s) of the Data
We extract values from a range of global datasets to points for some E. coli analysis.
Ah, Paris! The beautiful Seine! As the Olympics slowly fade from memory, some may recall that our triathletes were exposed to E. coli in the Seine River and experienced some unpleasant and performance diminishing gastrointestinal distress. I, too, have been swimming with E. coli recently, but in a very different, though no less distressful context. (My astute colleague reminds me that E. coli is an indicator, not the cause of the gastrobugs, but it’s still not something you really want to mess with.)
Many of those who have been following along with the GIS Blog (Hi Mom!) will know that we’ve been doing a lot of analysis at a global scale with some water quality parameters. This probably explains a lot of the, shall we say, colourful language my tolerant colleagues in Forbes have been hearing coming out of my office lately. It’s proved a challenge in many ways that could occupy many many of these posts (Ed. no thank you). In this post and the next (sorry), I’ll outline how to do this type of analysis in relation to our E. coli modelling.
Global Data Sets
So the aim of this research is to see if we can model the levels of E. coli based on the values from other parameters at a global scale, things like the number of livestock, distance to the nearest water treatment plant, slope, elevation, runoff, and different types of landcover for a total of 31 parameters, meaning it’s a from of multiple regression. For example, here’s the layer of chickens per square kilometre:

Hard to make out at the global scale but suffice it to say that there are a lot of chickens out there! Can we statistically link counts of E. coli with these counts as well as other parameters? Over the past six months or so I’ve been bringing around 31 global datasets together from disparate sources (data wrangling in its truest sense) and with varying ranges of frustration. They are a mixture of vector and raster data. My colleague at AgResearch has provided me with a set of points that are sampling sites for E. coli, and for each of these points (15,831 of them) my aim to is to attach the values from each of the global datasets. Here they are:

Once I’ve extracted the data from all the datasets to the points, I can send off a spreadsheet that he can use for some statistical modelling. Then we should be able to extrapolate those predictions of E.coli to those areas where we have no sampling data.
Let’s start with how we got the raw data on the map above – I was sent a CSV file with the point data:

The magic stuff to get us started are the Lat and Long columns – these provide the latitude and longitude coordinates that will allow the points to be mapped. My assumption is that these are in WGS84, which is a pretty safe bet in the absence of any other information. This CSV can be added directly to a map where we can find it under Standalone Tables in the Contents:

To map these points, right-click on the table name and go to Create Points from Table > XY Table to Point

Setting the X and Y Coordinate boxes and giving the output file a name gets us the points on the map, as we saw above.

Our next steps are to extract the values from the global datasets to our points – I’ve got both vector and raster data to work with.
Extracting Vector Data to Points
Several of our global datasets are vector polygons so we’re into the realm of spatial joins to bring them together. I’ve got four spatial join tools to consider: Intersect, Identity, Union and Spatial Join. I can eliminate Union right off the bat because it only works with polygons. Any of the remaining three would work but a clear winner here is Intersect, because it will allow me to do several layers at once – the others can only join one layer at a time. Here’s how I can set it up – note I’ve set the Output Type to be Point. It would do this anyway, but just to be sure:

Once run, the attributes from all these layers will be joined to the point layer. I can judiciously delete any unneeded attributes to just keep what I need. This worked from most of the vector layers. I’ve got a layer of water treatment plants and one thing needed is the distance from each point to the nearest treatment plant. Near is the obvious tool to use here – it will calculate the straight-line distance between features and adds two new attributes to my points table (note that it doesn’t create a new output layer – new attributes are added to the input layer): WW_NEAR_ID (the object ID of the nearest feature) and WW_NEAR_DIST (the calculated distance). When run, I can see these distances:

An interesting issue arose here – most of the values are quite small – nothing is larger than 1. What units are these? Remember that when we created the points, the coordinate system was WGS84, a geographic projection system (so 3D) which uses decimal degrees as its units, so these are angles, not distances. Converting these to on-the-ground distances metres is actually a tricky thing to do properly because it depends on where on the earth you are. You could *very very roughly* approximate the distance by multiplying by 111,000 to get metres (at the equator, each degree of latitude is approximately 111 km, but this isn’t true everywhere. It’s also about the earth’s radius, which varies with latitude). My approach was to take my E. coli point and treatment plant layers, project them to a Projected Coordinate System, which gets their units in to metres and then run the Near tool. Then I can join that layer to my original points, add a new field and copy the distance values over.
Extracting Raster Data to Points
With points, I’ve got two good options here: Extract Values to Points and Extract Multi Values to Points. They both do exactly the same thing. I’d use the former if I only had one raster layer and the latter if I had more than one raster layer to extract from. This will be a big time saver:
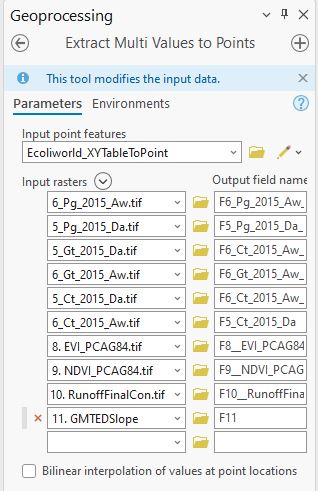
With this done I’ve got all the data needed attached to all the points. There are some Null values where the global datasets don’t cover the same extents as my points, but we just have to live with that one. This layer is currently a feature class in a geodatabase, which is a format my colleague can’t work with – he’d prefer an Excel spreadsheet. No worries: the Table to Excel tool will do the trick for me.

Here’s the output:

I’ll just add in a data dictionary and zip it off, job done.
Doing this sort of thing with points is relatively straightforward and this took about three hours in total once I had all the data set up – not too bad. As we’ll see in the next post, phase two of this meant extracting these same data to polygons, river catchments to be exact. This seriously increased the complexity and computation time (cue lots more colourful language) but that’s a post for another day. If this effort was a 100 m dash, the next is more like a triathlon, followed by a marathon with the shot put thrown in for good measure (but no break dancing).
C